2017-05-07
Implementation of Bellman-Ford Algorithm
blogentry, programming, bellmanford, c
blogentry, programming, bellmanford, c
I've already implemented Dijkstra's algorithm and was looking for another way to find the shortest path between two nodes in a graph. I found a simpler algorithm based on relaxation called "Bellman-Ford" algorithm.
I just implemented the algorithm in C# and would like to share it.
I had many troubles implementing Dijkstra's algorithm because I didn't have a good understanding of how it worked. So this time, I watched more videos on the Bellman-Ford algorithm to grasp the idea behind it.
Here are the videos I found helpful.
Watch the Theory video first before diving into example video.
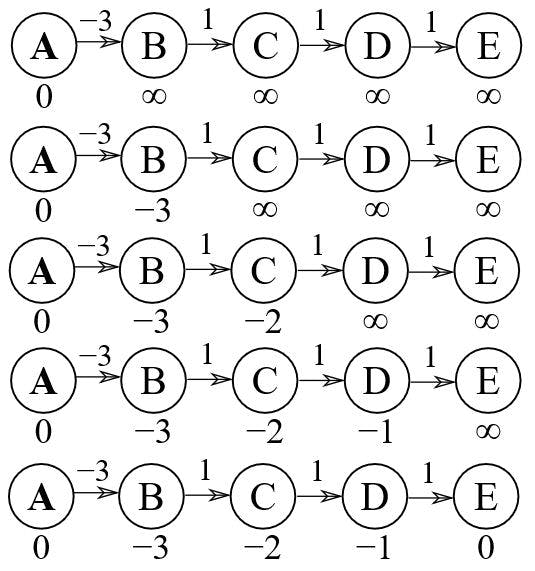
Theory and examples behind Bellman-Ford are very well explained in the videos and on Wikipedia so I won't go over them. I will only show a concrete implementation in C#. The implementation is based purely on algorithm listed in Wikipedia.
Wikipedia Pseudo Code
This is the pseudo code I will base my implementation.
1function BellmanFord(list vertices, list edges, vertex source)2 ::distance[],predecessor[]3
4 // This implementation takes in a graph, represented as5 // lists of vertices and edges, and fills two arrays6 // (distance and predecessor) with shortest-path7 // (less cost/distance/metric) information8
9 // Step 1: initialize graph10 for each vertex v in vertices:11 distance[v] := inf // At the beginning , all vertices have a weight of infinity12 predecessor[v] := null // And a null predecessor13
14 distance[source] := 0 // Except for the Source, where the Weight is zero15
16 // Step 2: relax edges repeatedly17 for i from 1 to size(vertices)-1:18 for each edge (u, v) with weight w in edges:19 if distance[u] + w < distance[v]:20 distance[v] := distance[u] + w21 predecessor[v] := u22
23 // Step 3: check for negative-weight cycles24 for each edge (u, v) with weight w in edges:25 if distance[u] + w < distance[v]:26 error "Graph contains a negative-weight cycle"27 return distance[], predecessor[]
Before showing my implementation, I need to show you the data structure of Graph and its associated classes, Node, and Edge because the declaration of the implementing method looks different from that of the pseudo code.
Here is my Graph data structure.
1public class Graph<T>2{3 public List<Node<T>> Nodes { get; set; }4
5 public Dictionary<Node<T>, Edge<T>> Vertices { get; } = new Dictionary<Node<T>, Edge<T>>();6
7 public void AddVertex(Node<T> node, Edge<T> edges)8 {9 if (!Vertices.ContainsKey(node))10 Vertices.Add(node, edges);11 }12 ...13}
And Node class representing a node in a graph.
1public class Node<T>2{3 public T Value { get; set; }4
5 public Node(T value)6 {7 Value = value;8 }9...10}
And also, my implementation of the graph has a class called "Edge" which is a line between two nodes and contains a weight and a linked node.
1public class Edge<T>2{3 public int Weight { get; set; }4 public Node<T> Node { get; set; }5
6 public Edge(int weight, Node<T> node)7 {8 Weight = weight;9 Node = node;10 }11...12}
Here is the implementing method definition.
1public Tuple<Dictionary<Node<T>, int>, Dictionary<Node<T>, Node<T>>>2 GetPathInfoUsingBellmanFordAlgorithm(Node<T> sourceNode)
Currently, the method GetPathInfoUsingBellmanFordAlgorithm belongs to "Graph" (I will refactor it later), which contains vertices and edges so only "sourceNode" is passed to it (thus leaving out "vertices" and "edges" parameter declarations in pseudo code).
::distance[],predecessor[] is implemented as two dictionaries as shown.
1var distance = new Dictionary<Node<T>, int>();2var predecessor = new Dictionary<Node<T>, Node<T>>();
distance represents distances from source to the node being checked while predecessor holds paths between nodes.
Each step in pseudo code is implemented as following.
Step 1: initialize graph
1// Step 1: initialize graph2foreach (KeyValuePair<Node<T>, Edge<T>> vertex in this.Vertices)3{4// At the beginning , all vertices have a weight of infinity5distance[vertex.Key] = int.MaxValue;6// And a null predecessor7predecessor[vertex.Key] = null;8
9 // initialize nodes in edges10 foreach (var edge in vertex.Value)11 {12 distance[edge.Node] = int.MaxValue;13 predecessor[edge.Node] = null;14 }15
16}17// Except for the Source, where the Weight is zero18distance[sourceNode] = 0;
Notice that I am initializing all vertices as well as nodes associated with each vertex because my implementation of vertices contains only vertices that have an outbound link(s) to another node.
The code is not yet optimized (since each edge can contain nodes that are already initialized) for demonstration purposes only to show 1 to 1 matching between my implementation and the Wikipedia pseudo code.
Step 2: relax edges repeatedly
1// Step 2: relax edges repeatedly2for (int i = 1; i < this.Vertices.Count; i++)3{4foreach (KeyValuePair<Node<T>, Edge<T>> vertex in this.Vertices)5{6var u = vertex.Key;7foreach (Edge<T> edge in vertex.Value)8{9var v = edge.Node;10var w = edge.Weight;11
12 if (distance[u] + w < distance[v])13 {14 distance[v] = distance[u] + w;15 predecessor[v] = u;16 }17 }18 }19
20}
In the pseudo code, there are only two for loops but the implementation has three due to the not-so-optimal data structure.
Step 3: check for negative-weight cycles
1// Step 3: check for negative-weight cycles2foreach (KeyValuePair<Node<T>, Edge<T>> vertex in this.Vertices)3{4var u = vertex.Key;5foreach (Edge<T> edge in vertex.Value)6{7var v = edge.Node;8var w = edge.Weight;9
10 if (distance[u] + w < distance[v])11 throw new InvalidOperationException("Graph contains a negative-weight cycle");12 }13
14}
As it was the case for step 2, this implementation has additional "foreach" loop to iterate over each edge in each vertex.
Step 4: return result
return Tuple.Create(distance, predecessor);
Since C# doesn't allow returning multiple values from a method, I am returning the distance and the predecessor as a tuple. I will refactor it later wrapping the result in another class object.
Now the question is, how do you determine the shortest path between two nodes from the return value?
One of the return values, predecessor, contains information on how to traverse between two nodes.
Let's use this weighted graph as an example (Example is from this YouTube video.)

The shortest path between "A" and "F" is "A->B->E->G->F".
The predecessor returned by the method, GetPathInfoUsingBellmanFordAlgorithm looks like this.

To find the shortest path, we need to traverse from the destination back to the source node.
So when we start from 6th item(where index is 5 [F,G]), the value in the dictionary is "G". Next, we look for an item where "G" is the key in the predecessor. We find that the 7th item (G,E) has "G" as the key. Then iterate until we reach the source node, "A". Since we are traversing backward, it seems like a stack would do the job to return the result in LIFO order.
The implementation of a method that returns the shortest path looks like this.
1public List<Node<T>> GetShortestPathUsingBellmanFordAlgorithm(Node<T> fromNode, Node<T> toNode)2{3// Get the predecessor4Tuple<Dictionary<Node<T>, int>, Dictionary<Node<T>, Node<T>>> pathInfo =5 GetPathInfoUsingBellmanFordAlgorithm(fromNode);6var predecessors = pathInfo.Item2;7
8 // Initialize the stack with start node, which is the destination9 Stack<Node<T>> result = new Stack<Node<T>>();10 var startNode = toNode;11 result.Push(startNode);12
13 // Traverse the predecessor hashtable until we find14 do15 {16 var node = predecessors[startNode];17 result.Push(node);18
19 // if we reached the source, then we are done.20 if (node.Value.Equals(fromNode.Value)) break;21
22 // Move to the next node23 startNode = node;24 } while (true);25
26 return result.ToList();27}
After the getting the predecessor from "GetPathInfoUsingBellmanFordAlgorithm", the code simply traverses the predecessor hash table in reverse order and stores each step in a stack.
I can't stress enough that the code is not production ready because it's just a demo implementation. The full source is available on GitHub. You can copy it, modify it, use it, distribute it any way you want/need to.
I've described how Bellman-Ford algorithm is implemented in C#. I am planning to refactor it to be more readable and structure the code properly and will push the updated code on GitHub.